AccountsDB
Main code is in src/accounts-db/
The main files include:
db.zig: Includes the main database structAccountsDBaccounts_file.zig: Includes the main struct for reading + validating account filesindex.zig: All index-related structs (account ref, simd hashmap, …)snapshots.zig: Fields + data to deserialize snapshot metadatabank.zig: Minimal logic for bank (still being built out)genesis_config.zig: Genesis config fieldssysvars.zig: System variables definitions and addresses (clock, slot_history, …)
Cli options
--help output of accounts-db related flags:
-s, --snapshot-dir <snapshot_dir> path to snapshot directory (where snapshots are downloaded and/or unpacked to/from) - default: test_data/
-t, --n-threads-snapshot-load <n_threads_snapshot_load> number of threads to load snapshots: - default: ncpus
-u, --n-threads-snapshot-unpack <n_threads_snapshot_unpack> number of threads to unpack snapshots - default: ncpus * 2
-d, --disk-index-path <disk_index_path> path to disk index - default: no disk index, index will use ram
-f, --force-unpack-snapshot force unpack snapshot even if it exists
--min-snapshot-download-speed <min_snapshot_download_speed_mb> minimum download speed of full snapshots in megabytes per second - default: 20MB/s
--force-new-snapshot-download force download of new snapshot (usually to get a more up-to-date snapshot)
-t, --trusted_validator <Trusted Validator> public key of a validator whose snapshot hash is trusted to be downloaded
Additional context on specific cli flags is given throughout these docs.
Background
Snapshots
Snapshots contain the full state of the blockchain (including all accounts) at a specific slot. They are requested/downloaded from existing validators in the network and are used to bootstrap new validators (instead of starting from Genesis).
the typical snapshot layout is as follows:

When starting up, we use SnapshotFiles.find with the snapshot directory string
to find the highest snapshot file that exists. If it doesnt exist, then a new
snapshot is downloaded.
Account files
A snapshot contains multiple account files which contain all the accounts for a specific slot. Each file is organized as a list of accounts (represented by the raw bytes).

Startup
On startup, the validator does the following:
- Snapshots are downloaded from peers
- The snapshot is decompressed into multiple account files
- Each account file is mmap'd into memory and validated
- The account index is generated by reading each account file (where the index maps pubkeys to the location of the corresponding account)
- The accounts-db state is validated to ensure no data corruption occurred
note: if --force-unpack-snapshot is used, then a snapshot is always downloaded. if not and an accounts/ directory exists then
it will attempt to load using the accounts located in that directory.
Creating a AccountsDB instance
var accounts_db = try AccountsDB.init(
allocator, // any allocator used for all operations
logger, // used for outputting progress/info/debug details
.{} // custom configuration (defaults are reasonable)
);
defer accounts_db.deinit();
For more usage examples, checkout the tests by searching for test "accountsdb in
the codebase.
We'll cover how to load accounts db from a snapshot later in the docs.
Architecture
The two major components in the db include:
- A
account_filemap which maps afile_idto the mmap'd contents of that file - The account index which maps a pubkey to a file_id and an offset of where the account's bytes begin
The account_file map uses a std hashmap and is straightforward.
The account index is more involved.
Account index
The account index shards pubkeys across multiple bins where each pubkey is associated with a specific bin based on the pubkey’s first N bits. This allows for parallel read/write access to the database (locking only a single bin for each lookup vs the entire struct).
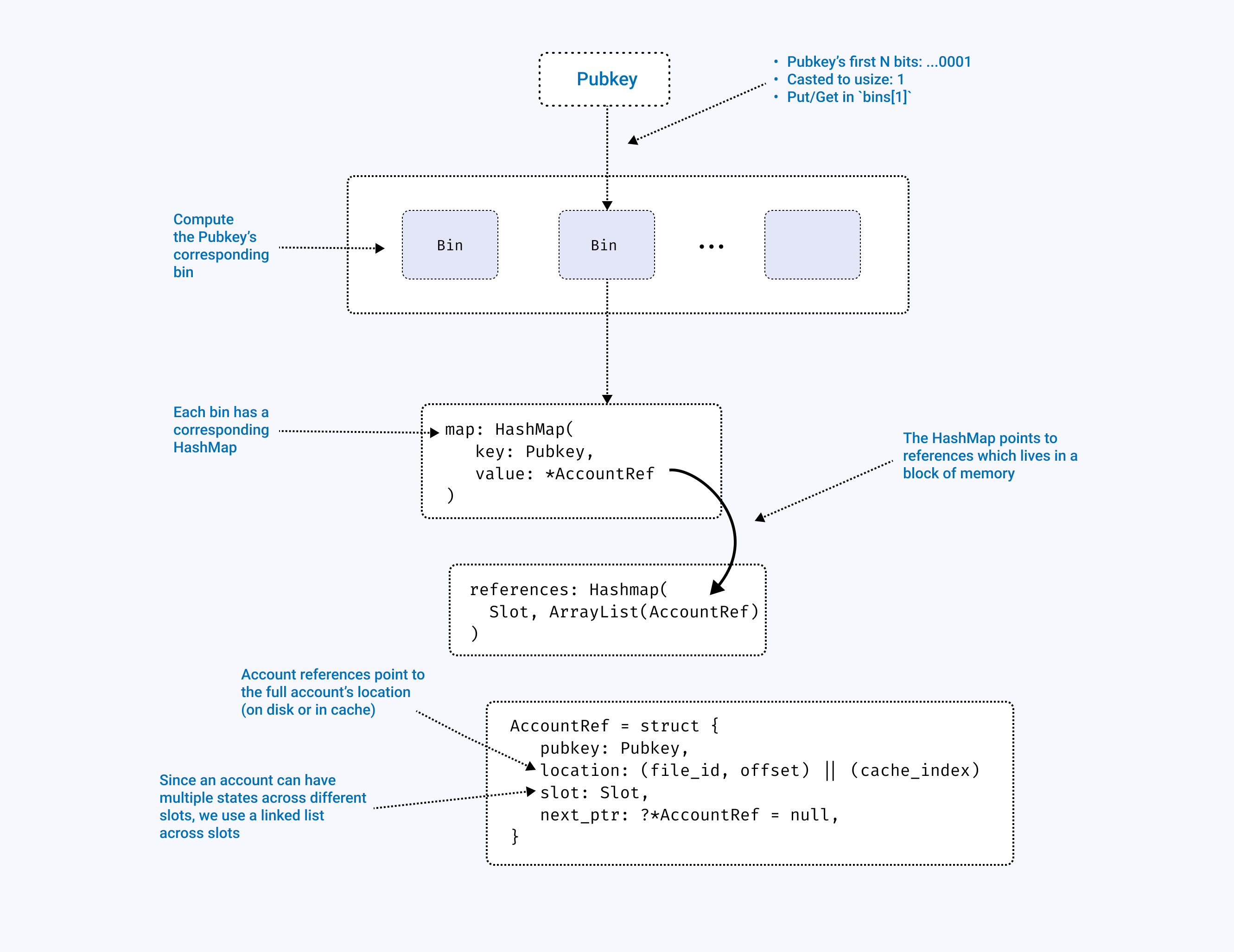
Due to the large amount of accounts on solana, storing all account references
in ram would be very expensive - which is why we also support storing account
indexes (more specifically, the references ArrayList) on disk using
a backing file.
High-performance hashmap: SwissMap struct
To achieve fast read/write speeds, we needed to implement our own hashmap
based on Google's Swissmap. We saw 2x improvement on getOrPut calls for reads and writes.
Disk-based allocator: DiskMemoryAllocator
To support disk-based account references, we created a general purpose disk allocator which creates memory from mmap-ing files stored on disk.
// files are created using `test_data/tmp_{i}` format where `i` is
// incremented by one for each alloc call.
var allocator = try DiskMemoryAllocator.init("test_data/tmp");
defer allocator.deinit(null);
Methods
Downloading a snapshot
All the code can be found in src/accountsdb/download.zig : downloadSnapshotsFromGossip
First, there are two types of snapshots: full snapshots and incremental snapshots
- Full snapshots include all the accounts on the network at some specific slot.
- Incremental snapshots are smaller and only contain the accounts which changed from a full snapshot.
For example, if the network is on slot 100, the full snapshot could contain all accounts at slot 75, and a matching incremental snapshot could contain all accounts that changed between slot 75 and slot 100.
To download a snapshot, gossip is started up to find other nodes in the network and collect gossip data - we look for peers who
- Have a matching shred version (ie, the network version/hard-forks)
- Have a valid rpc socket (ie, can download from)
- Have a snapshot hash available
The snapshot hash structure is a gossip datatype which contains
- The largest full snapshot (both a the slot and hash)
- A list of incremental snapshots (also slot and hash)
When downloading,
- Prioritize snapshots with larger slots
- If we have a list of 'trusted' validators, we only download snapshots whos hashes matches the trusted validators hashes
Then for each of these valid peers, we construct the url of the snapshot:
- Full: snapshot-{slot}-{hash}.tar.zst
- Incremental: incremental-snapshot-{base_slot}-{slot}-{hash}.tar.zst
And then start the download - we periodically check the download speed and make sure its fast enough, or we try another peer
Decompressing a snapshot
Snapshots are downloaded as .tar.zst and we decompress them using parallelUnpackZstdTarBall
We use a zstd library C bindings to create a decompressed stream which we then
feed the results to untar the archive to files on disk. the unarchiving
happens in parallel using n-threads-snapshot-unpack. since there is
a large amount of I/O, the default value is 2x the number of CPUs on the machine.
Loading from a snapshot
Loading from a snapshot begins in accounts_db.loadFromSnapshot is a very
expensive operation.
The steps include:
- Read and load all the account files
- Validates + indexes every account in each file (in parallel)
- Combines the results across the threads (also in parallel)
To achieve this in parallel we split processing the account files across multiple threads (part1 of the diagram below) - this means each thread:
- Reads and mmaps every account file
- Creates and populates an
ArrayList(AccountRef)with every account it parses from the account files - Populates their own sharded index by binning the pubkeys and populating
the hashmap with the
*AccountRefs
The result is N threads (--n-threads-snapshot-load decides the value for N) each with their own account index, which we now need
to combine. to combine indexes we merge index bins in parallel across threads.
For example, one thread will merge bins[0..10] another will merge bins [10..20], ... etc for all the bins across all the threads.
This approach generates the index with zero locks
validating a snapshot
note: this will likely change with future improvements to the solana protocol account hashing
The goal of validating snapshots is to generate a merkle tree over all the accounts in the db and compares the root hash with the hash in the metadata. the entrypoint
is validateLoadFromSnapshot.
We take the following approach:
- Account hashes are collected in parallel across bins using
getHashesFromIndexMultiThread- similar to how the index is generated - Each thread will have a slice of hashes, the root hash is computed against these nested slices using
NestedHashTree
note: pubkeys are also sorted so results are consistent
Validating other metadata
After validating accounts-db data, we also validate a few key structs:
GenesisConfig: This data is validated in against the bank inBank.validateBankFields(bank.bank_fields, &genesis_config);Bank: Containsbank_fieldswhich is in the snapshot metadata (not used right now)StatusCache / SlotHistory Sysvar: Additional validation performed instatus_cache.validate
Benchmarks
BenchArgs (found at the bottom of db.zig) contains the configuration of a benchmark (comments describe each parameter)
- Writing accounts uses
putAccountBatchwhich takes a slice of accounts andputAccountFile(file) - Reading accounts uses
accounts_db.getAccount(pubkey)